

style1
Procédurier - Utiliser R en mesure et évaluation
Section 08 D - Analyse du PISA par la théorie des réponses aux items.
Nous avons abordé dans la section 07 la TRI du point de vue de trouver les valeurs des coefficients. Ici, nous nous concentrerons sur la représentation graphique des résultats d'un test, en vous laissant le calcul des coefficients.
##############################################################################
## Fichier: Section_08D_alpha.r date: janvier 2008
## Auteur: AndréSèb Aubin (andreseb.aubin@gmail.com)
##
## Dans ce script
## Analyse de données du PISA par la théorie de la répone à l'item
##
## Fichier initial de donnée: math_booklet9_01a.dat (fait dans le script Section_08A_alpha.r)
## Vérification du nombre de facteurs
##
##############################################################################
##############################################################################
## 00 - Fonctions permettant d'initialiser l'environnement R
##############################################################################
rm(list=ls(all=TRUE))
library("grDevices")
setwd("C:/Users/AndreSeb/Desktop/TDII_Omega/Activite_finale/bin")
#setwd("C:/Documents and Settings/André-Sébastien/Mes documents/doctorat/TDII_Omega/Activite_finale/bin")
# setwd(choose.dir()) # À activer si on veut choisir le répertoire à chaque fois
# setwd("F:/PISA/bin") # Autre choix de répertoire (pour une clé USB par exemple)
##############################################################################
## 01 - Importation du fichier math_booklet9_01a.dat dans la matrice donnees_brutes
##############################################################################
donnees_brutes <- read.table(file="math_booklet9_01a.dat", header = TRUE)
Dimension <- dim(donnees_brutes)
Dimension
# Pour notre objectif, nous allons retirer les lignes (donc les étudiants) ayant un ou plusieurs NA
donnees <- na.omit(donnees_brutes)
Dimension2 <- dim(donnees)
Dimension2
nbre_etudiant = Dimension2[1]
nbre_etudiant
nbre_question = Dimension2[2]
nbre_question
donnees <- round(donnees, 2)
score_etudiant <- rowSums(donnees)
moyenne_test <- mean(score_etudiant)
moyenne_test
ecart_type <- sd(score_etudiant)
ecart_type <- round(ecart_type, 1)
ecart_type
score_z <- (score_etudiant-moyenne_test)/ecart_type
score_z <- round(score_z, 1)
donnees <- cbind(donnees, score_z)
write.table(donnees, file="math_booklet9_na_omit.dat", row.names=TRUE, col.names=TRUE, sep="\t")
##############################################################################
## 02 - Théorie des réponses aux items de mathématiques
##
## Il faut cependant, avant de faire l'analyse factorielle, ne laissez que les
## colonnes contenant des questions sur les sciences, les mathématiques et les sciences.
##
## Gestion des NA : les lignes avec des NA ont été omises dans donnees
##
## Matrice utilisée: donnees
## Représentation des courbes pour les seize questions de mathématiques.
##
##############################################################################
min_hab = -3*ecart_type
max_hab = 3*ecart_type
habilete <- seq(min_hab, max_hab, by=0.1)
habilete = round(habilete, 1)
final = 0
final <- length(habilete)
P_item = 0
P_item_compil = 0
increment = 0
increment2 = 0
Prop_item = 0
vProp_item_b = 0
P_item_b = 0
P_item_compil_b = 0
for (increment3 in 1:nbre_question)
{
for (increment2 in 1:final)
{
for (increment in 1:nbre_etudiant)
{
if(habilete[increment2] == score_z[increment])
{
P_item_b = P_item_b + donnees[increment,increment3]
}
}
P_item = P_item_b + P_item
P_item_compil_b[increment2] = P_item_b/nbre_etudiant
P_item_b = 0
P_item_compil[increment2] = P_item/nbre_etudiant
}
Prop_item_b = cbind(Prop_item_b, P_item_compil_b)
Prop_item = cbind(Prop_item, P_item_compil)
plot(habilete, Prop_item[,increment3])
P_item = 0
}
## Fichier: Section_08D_alpha.r date: janvier 2008
## Auteur: AndréSèb Aubin (andreseb.aubin@gmail.com)
##
## Dans ce script
## Analyse de données du PISA par la théorie de la répone à l'item
##
## Fichier initial de donnée: math_booklet9_01a.dat (fait dans le script Section_08A_alpha.r)
## Vérification du nombre de facteurs
##
##############################################################################
##############################################################################
## 00 - Fonctions permettant d'initialiser l'environnement R
##############################################################################
# setwd(choose.dir()) # À activer si on veut choisir le répertoire à chaque fois
# setwd("F:/PISA/bin") # Autre choix de répertoire (pour une clé USB par exemple)
##############################################################################
## 01 - Importation du fichier math_booklet9_01a.dat dans la matrice donnees_brutes
##############################################################################
# Pour notre objectif, nous allons retirer les lignes (donc les étudiants) ayant un ou plusieurs NA
##############################################################################
## 02 - Théorie des réponses aux items de mathématiques
##
## Il faut cependant, avant de faire l'analyse factorielle, ne laissez que les
## colonnes contenant des questions sur les sciences, les mathématiques et les sciences.
##
## Gestion des NA : les lignes avec des NA ont été omises dans donnees
##
## Matrice utilisée: donnees
## Représentation des courbes pour les seize questions de mathématiques.
##
##############################################################################
v
Voici le graphique d'une des questions (la quinzième).
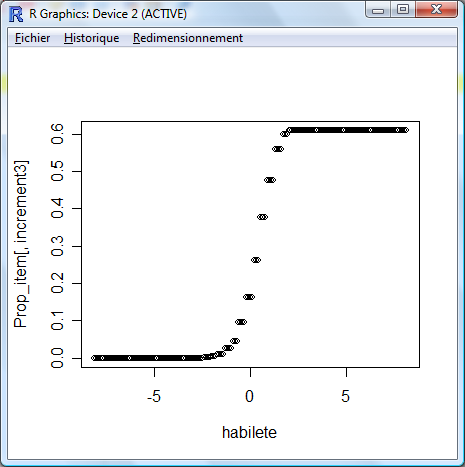
##############################################################################
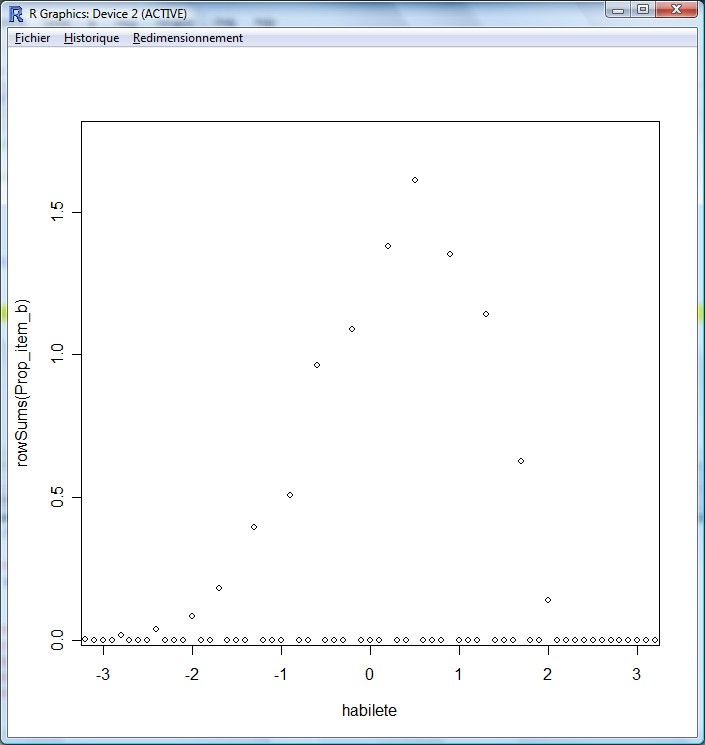
## 03 - Théorie des réponses aux items de mathématiques - Courbe d'information sur le test
##
##
## Gestion des NA : les lignes avec des NA ont été omises dans donnees
## Représentation compilée pour le test.
##
##############################################################################
####################### Fin du script Section_08D_alpha.r #####################
 Enregistrer sous...
Enregistrer sous...