

style1
Procédurier - Utiliser R en mesure et évaluation
Section 09 A - L'extraction de données du PISA 2006
Scripts d'initialisation de l'environnement R
Pour accéder à la page décrivant les choix de fichiers d'initialisation, cliquez ici. Sinon, pour uniquement accéder au script d'initialisation le plus récent, cliquez ici.
Extraction des données à partir du fichier SPSS de données.
Les opérations de la présente section sont inscrites dans le script Transfert_data_gamma.r disponible en cliquant ici.
Dans la présente section, nous prendrons un fichier de données externe et nous le rendrons compatible et donc utilisable dans l'environnement R. Le fichier sur lequel nous travaillerons est le suivant. Pour l'ensemble de la section 09, nous vous suggérons de créer un répertoire et d'y placer tous les éléments que vous ajouterez au fur et à mesure. L'ensemble des données et des fichiers peut dépasser 200 Mo (204 800 ko), assurez vous déjà d'avoir autant d'espace disponible.
Obtenir les données originales du PISA
Sur le site du PISA 2006, les données du PISA 2006 sont disponibles. Le fichier de départ que nous voulons importer a été formaté pour le logiciel SPSS qui est rarement installé sur les ordinateurs personnels et dont, de toutes façons, nous n'avons pas besoin ici.
Les répondants canadiens du PISA 2006
Nous avons, à l'aide SPSS, extrait des données obtenues sur le site Internet du PISA 2006, afin de ne retenir que les répondants canadiens. Ce sont ces données qui seront utilisés dans la section 9. Contrairement à ce qui a été fait dans la section 8, les données ici n'ont pas été modifiées, ce qui permettra de montrer le travail à faire pour analyser des données tirées de réelles bases de données.
Voici le fichier de données de départ. À cause du grand nombre de données, la version disponible ici est compressée. Pour utiliser le fichier, il faut donc:
1) Enregistrez le fichier dans un répertoire facile à retracer. Si vous avez une clé USB, un répertoire sur la racine (comme par exemple F:\PISA\) est probablement l'idéal. Enregistrer sous...
Enregistrer sous...
2) Il vous faut décompresser le fichier. Sur la plupart des ordinateurs, il existe déjà un logiciel pour décompresser les fichiers zip. En double-cliquant sur le fichier .zip, vous verrez si vous avez un tel logiciel. Sinon, nous avons expliqué comment décompresser un tel fichier sur la page suivante: cliquer ici
Afin de nous assurer que l'exécution se fera sans soucis, nous allons d'abord faire quelques manipulations dans R. La plus importante consiste à déterminer l'espace de travail, c'est-à-dire, l'endroit où nous allons prendre et déposer les différents fichiers utilisés. C'est la commande setwd() qui permet de déterminer l'espace de travail. Si vous utilisez toujours le même espace, choisssissez la solution (2), sinon la solution (1) permet de choisir à chaque exécution du script.
Notons que les étapes suivantes peuvent prendre un certain temps d'éxécution (quelques centaines de secondes). Cela s'explique par la taille des fichiers à traîter qui est importante (environ 66 méga-octets pour le plus gros fichiers). Ces fichiers contiennent en effet des milliers de répondants. Par exemple, le fichier initial contient 22 646 répondants et pour chaque répondant 337 informations diverses.
# NOM DU FICHIER: Transfert_data_gamma.r
# Créé le 7 juin 2009
#
# Résumé: Ce script permet
# 1) de récupérer les données du fichier de données PISA2006/INT_Cogn06_T_Dec07_CANADA.sav
# 2) d'entreposer ces résultats dans un fichier
# 3) de déterminer le répertoire de travail (WD)
# F_IN : PISA2006/INT_Cogn06_T_Dec07_CANADA.sav
# F_OUT: data_01b.dat; booklet8_01a_temp.dat; booklet8_01a.dat
#
# Variables internes: extract_data_2006 : reçoit contenu fichier SPSS (.sav)
# extract_data_01c
# booklet8
# booklet8_NA : booklet8 sans les NA
#===============================================================
## library("Hmisc") ## Déjà dans le fichier d'initialisation
## setwd(choose.dir()) ## Déjà dans le fichier d'initialisation
## setwd("G:/Activite_finale/bin") ## Déjà dans le fichier d'initialisation
## Importer dans l'environnement R, le fichier PISA2006/INT_Cogn06_T_Dec07_CANADA.sav
## contenant toutes les données des répondants du Canada (format SPSS)
# extract_data_2006_b <- spss.get("PISA2006/INT_Cogn06_T_Dec07_CANADA.sav", to.data.frame=TRUE, use.value.labels=FALSE) ## gros fichier 66 Mo
# View(extract_data_2006_b)
La fonction View est utile pour naviguer dans des les données de grande dimensions.
Le résultat de cette fonction est donnée dans la figure suivante qui montre les premières colonnes du tableau de données.
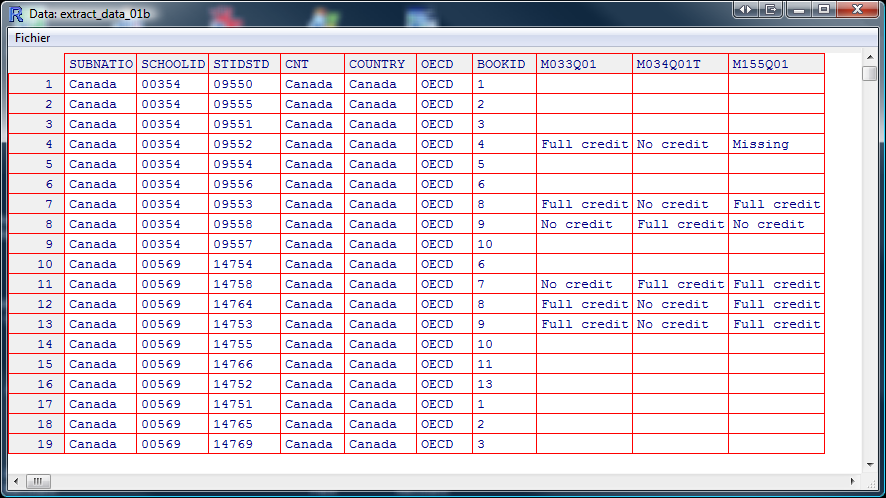
Voici les dernière colonnes. Cela confirme le fait qu'en plus des questions de lecture, de sciences et de mathématiques, le fichier contient d'autres informations qui, dans la présente section, ne seront pas utiles.
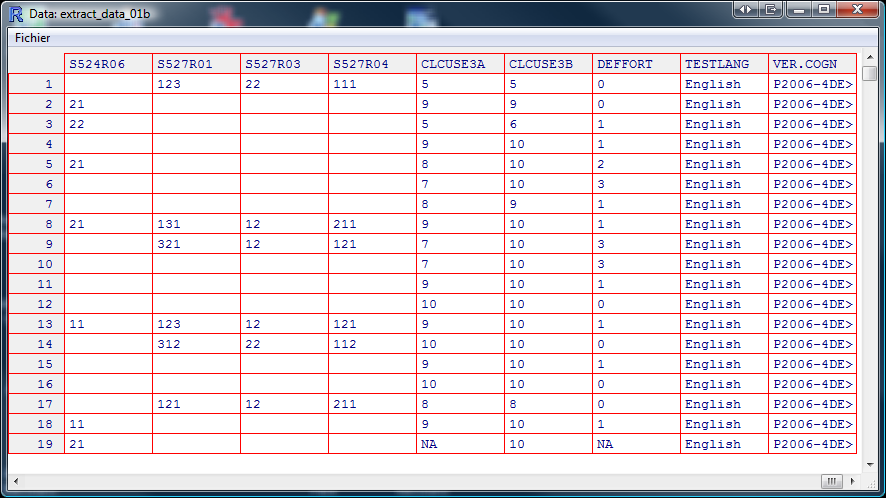
Enregistrons les données extraites dans un fichier (qui pourrait servir plus tard).
## write.table(extract_data_01, file="data_01.dat", row.names=TRUE, col.names=TRUE, sep="\t")
Les opérations suivantes permettent de créer le tableau de données booklet8_final3 en extrayant uniquement les données du livret 8. Il s'agit de la même procédure, à peu près que celle de la section 08A.
## Cela donne un sous-échantillon de tout ceux qui ont répondu au Booklet no. 8
## Cependant, ce sous-échantillon a les réponses à toutes les questions possibles, même celle qui en figure pas dans le Booklet no. 8 (réponse NA).
## L'avantage est que les réponses NA sont différentes des réponses "n'a pas répondu".
## Enlevons les colonnes qui ne serviront pas dans le cadre du présent exercice.
## D'abord, retirons les 8 premières colonnes.
# booklet8_final[[indice]]
On obtient donc le tableau de données booklet8_final3. Ce tableau contient des éléments en texte.
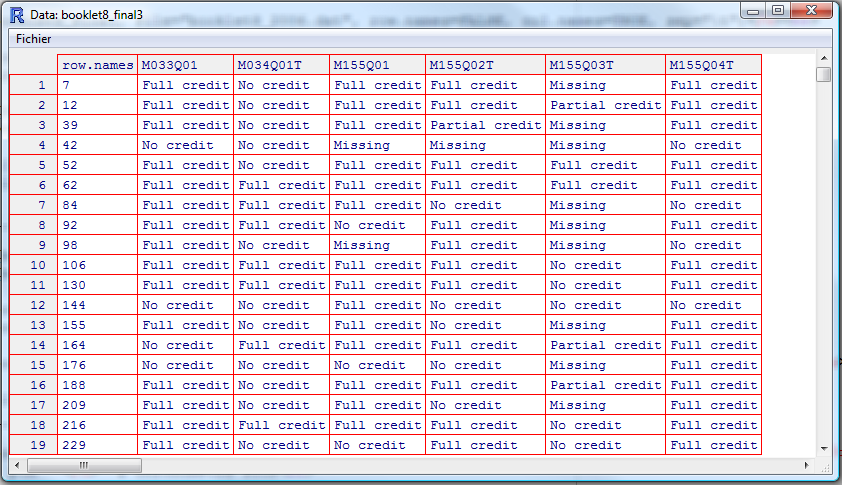
Le script transtype_alpha.r permet de transformer booklet8_final3 en une matrice d'éléments numériques uniquement.
# NOM DU FICHIER: initialisation_delta.r
# Créé le 7 juin 2009
#
# Résumé: Ce script permet
# 1) de transformer les éléments tirés du PISA2006 en une matrice utile avec la fonction gpcm()
#
# F_in: booklet_final3 (obtenu avec Transfert_data_gamma.r)
# F_out: data1 (matrice avec uniquement des valeurs 0,1,2 et NA)
#===============================================================
#View(booklet8_final3)
## Initialiser une matrice purement numérique
#View(data1)
## Il faut, pour que les fonctions gpcm et grm fonctionnent, que les valeurs soient
## établies selon une graduation fixe (ex. 0,1,2).
## Valeurs de chaque élément (peuvent être changées si désiré)
##============================================================================
## Les fonctions which() servent à remplacer les éléments de booklet8_final3 par
## des équivalents numériques.
##============================================================================
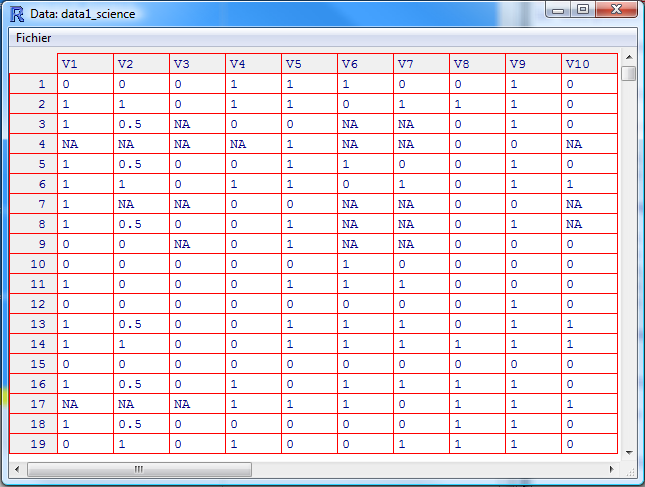
## Vérification du passage de booklet8_final3 à data1

Les dernières lignes du script servent à séparer en deux matrices les questions de mathématiques des questions de sciences.

Pour accéder à la suite des manipulations de la section 09 Cliquez ici (Section_09_B).
Dernière mise à jour faite le 21 janvier 2017 à 13:10 -0800 par AndréSèb |
|

|